Attacking ML-based Systems (ML OWASP Top 10)
Just like for Web Applications, Web APIs, and Mobile Applications, OWASP has published a Top 10 list of security risks regarding the deployment and management of ML-based Systems, the Top 10 for Machine Learning Security. We will briefly discuss the ten risks to obtain an overview of security issues resulting from ML-based systems.
Input Manipulation Attack (ML01)
As the name suggests, input manipulation attacks comprise any type of attack against an ML model that results from manipulating the input data. Typically, the result of these attacks is unexpected behavior of the ML model that deviates from the intended behavior. The impact depends highly on the concrete scenario and circumstances in which the model is used. It can range from financial and reputational damage to legal consequences or data loss.
Many real-world input manipulation attack vectors apply small perturbations to benign input data, resulting in unexpected behavior by the ML model. In contrast, the perturbations are so small that the input looks benign to the human eye. For instance, consider a self-driving car that uses an ML-based system for image classification of road signs to detect the current speed limit, stop signs, etc. In an input manipulation attack, an attacker could add small perturbations like particularly placed dirt specks, small stickers, or graffiti to road signs. While these perturbations look harmless to the human eye, they could result in the misclassification of the sign by the ML-based system. This can have deadly consequences for passengers of the vehicle. For more details on this attack vector, check out this and this paper.
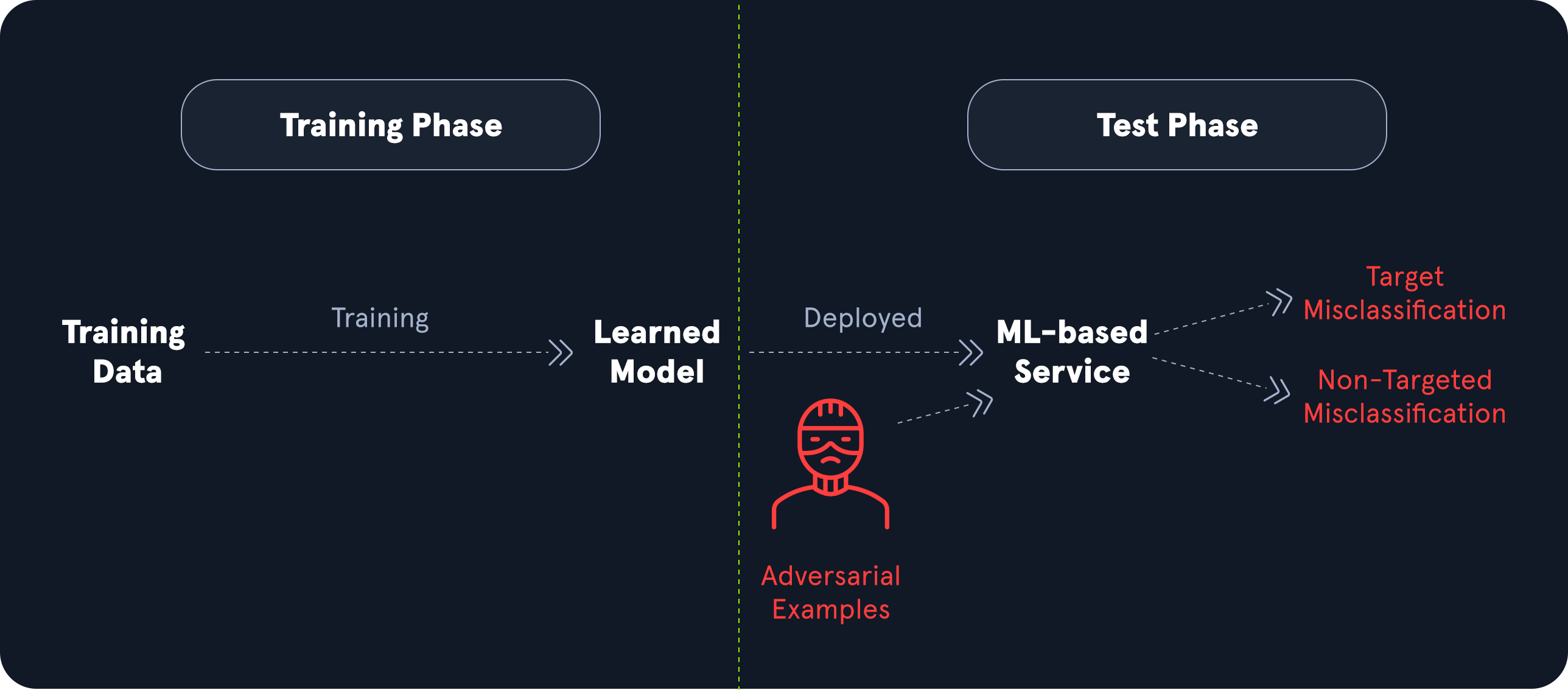
Data Poisoning Attack (ML02)
Data poisoning attacks on ML-based systems involve injecting malicious or misleading data into the training dataset to compromise the model's accuracy, performance, or behavior. As discussed before, the quality of any ML model is highly dependent on the quality of the training data. As such, these attacks can cause a model to make incorrect predictions, misclassify certain inputs, or behave unpredictably in specific scenarios. ML models often rely on large-scale, automated data collection from various sources, so they may be more susceptible to such tampering, especially when the sources are unverified or gathered from public domains.
As an example, assume an adversary is able to inject malicious data into the training data set for a model used in antivirus software to decide whether a given binary is malware. The adversary may manipulate the training data to effectively establish a backdoor that enables them to create custom malware, which the model classifies as a benign binary. More details about installing backdoors through data poisoning attacks are discussed in this paper.
Model Inversion Attack (ML03)
In model inversion attacks, an adversary trains a separate ML model on the output of the target model to reconstruct information about the target model's inputs. Since the model trained by the adversary operates on the target model's output and reconstructs information about the inputs, it inverts the target model's functionality, hence the name model inversion attack.
These attacks are particularly impactful if the input data contains sensitive information—for instance, models processing medical data, such as classifiers used in cancer detection. If an inverse model can reconstruct information about a patient's medical information based on the classifier's output, sensitive information is at risk of being leaked to the adversary. Furthermore, model inversion attacks are more challenging to execute if the target model provides less output information. For instance, successfully training an inverse model becomes much more challenging if a classification model only outputs the target class instead of every output probability.
An approach for model inversion of language models is discussed in this paper.
Membership Inference Attack (ML04)
Membership inference attacks seek to determine whether a specific data sample was included in the model's original training data set. By carefully analyzing the model's responses to different inputs, an attacker can infer which data points the model "remembers" from the training process. If a model is trained on sensitive data such as medical or financial information, this can pose serious privacy issues. This attack is especially concerning in publicly accessible or shared models, such as those in cloud-based or machine learning-as-a-service (MLaaS) environments. The success of membership inference attacks often hinges on the differences in the model's behavior when handling training versus non-training data, as models typically exhibit higher confidence or lower prediction error on samples they have seen before.
An extensive assessment of the performance of membership inference attacks on language models is performed in this paper.
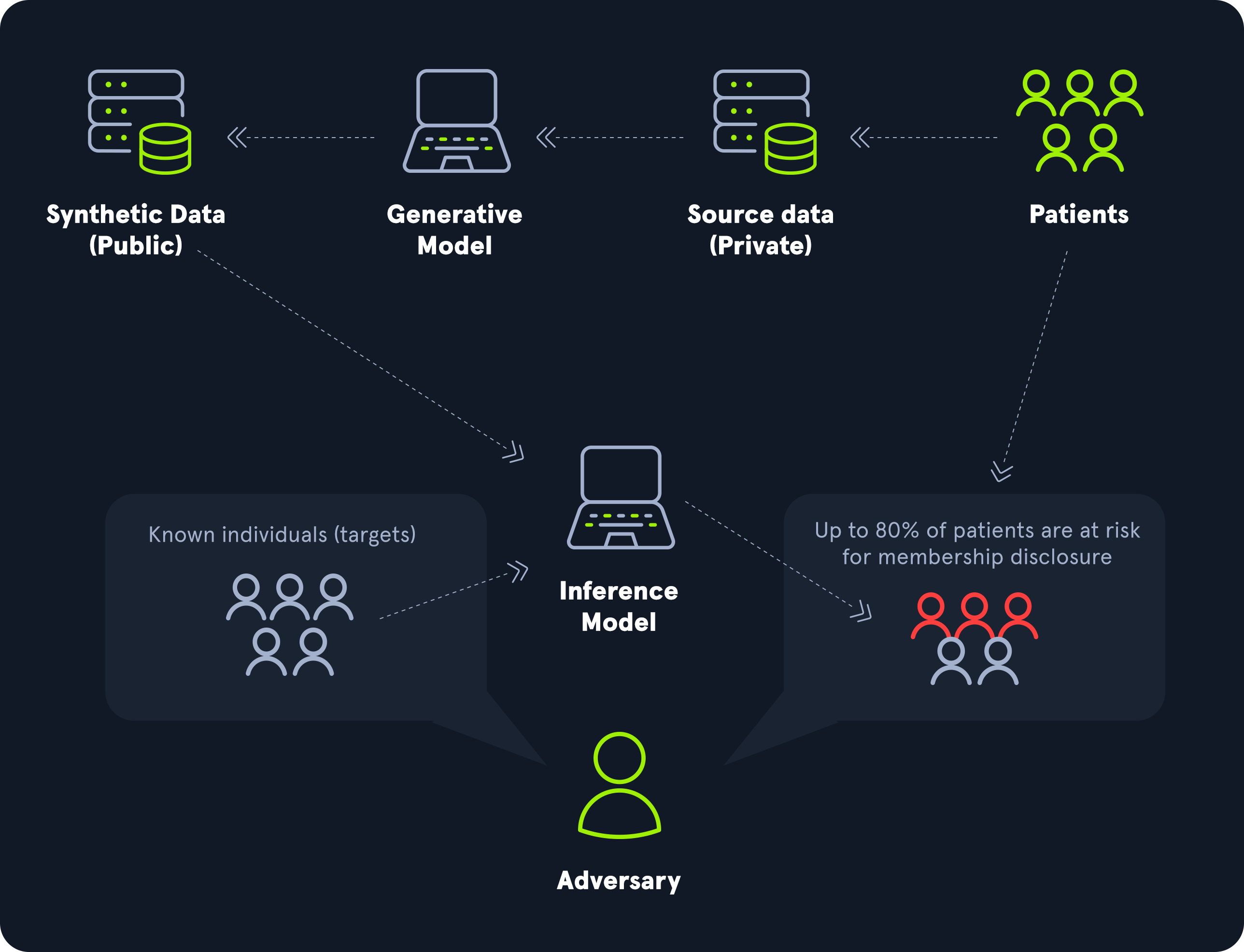
Model Theft (ML05)
Model theft or model extraction attacks aim to duplicate or approximate the functionality of a target model without direct access to its underlying architecture or parameters. In these attacks, an adversary interacts with an ML model and systematically queries it to gather enough data about its decision-making behavior to duplicate the model. By observing sufficient outputs for various inputs, attackers can train their own replica model with a similar performance.
Model theft threatens the intellectual property of organizations investing in proprietary ML models, potentially resulting in financial or reputational damage. Furthermore, model theft may expose sensitive insights embedded within the model, such as learned patterns from sensitive training data.
For more details on the effectiveness of model theft attacks on a specific type of neural network, check out this paper.
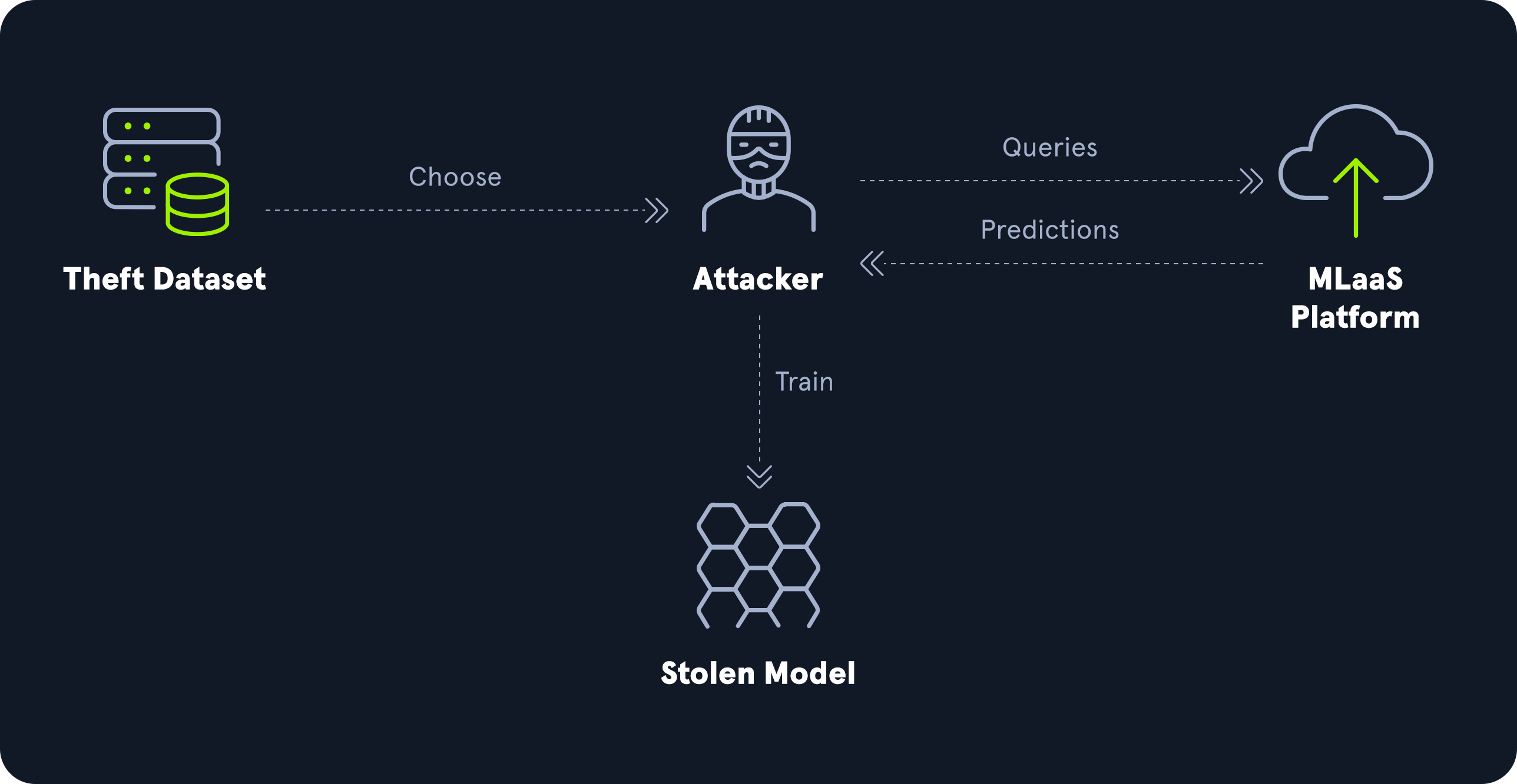
AI Supply Chain Attacks (ML06)
Supply chain attacks on ML-based systems target the complex, interconnected ecosystem involved in creating, deploying, and maintaining ML models. These attacks exploit vulnerabilities in any part of the ML pipeline, such as third-party data sources, libraries, or pre-trained models, to compromise the model's integrity, security, or performance. The supply chain of ML-based systems consists of more parts than traditional IT systems due to the dependence on large amounts of data. Details of supply chain attacks, including their impact, depend highly on the specific vulnerability exploited. For instance, they can result in manipulated models that perform differently than intended. The risk of supply chain attacks has grown as ML systems increasingly rely on open-source tools, publicly available datasets, and pre-trained models from external sources.
For more general information about supply chain attacks, check out the Supply Chain Attacks module.
Transfer Learning Attack (ML07)
Open-source pre-trained models are used as a baseline for many ML model deployments due to the high computational cost of training models from scratch. New models are then built on top of these pre-trained models by applying additional training to fine-tune the model to the specific task it is supposed to execute. In transfer learning attacks, adversaries exploit this transfer process by manipulating the pre-trained model. Security issues such as backdoors or biases may arise if these manipulations persist in the fine-tuned model. Even if the data set used for fine-tuning is benign, malicious behavior from the pre-trained model may carry over to the final ML-based system.
Model Skewing (ML08)
In model skewing attacks, an adversary attempts to deliberately skew a model's output in a biased manner that favors the adversary's objectives. They can achieve this by injecting biased, misleading, or incorrect data into the training data set to influence the model's output toward maliciously biased outcomes.
For instance, assume our previously discussed scenario of an ML model that classifies whether a given binary is malware. An adversary might be able to skew the model to classify malware as benign binaries by including incorrectly labeled training data into the training data set. In particular, an attacker might add their own malware binary with a benign label to the training data to evade detection by the trained model.
Output Integrity Attack (ML09)
If an attacker can alter the output produced by an ML-based system, they can execute an output integrity attack. This attack does not target the model itself but only the model's output. More specifically, the attacker does not manipulate the model directly but intercepts the model's output before the respective target entity processes it. They manipulate the output to make it seem like the model has produced a different output. Detection of output integrity attacks is challenging because the model often appears to function normally upon inspection, making traditional model-based security measures insufficient.
As an example, consider the ML malware classifier again. Let us assume that the system acts based on the classifier's result and deletes all binaries from the disk if classified as malware. If an attacker can manipulate the classifier's output before the succeeding system acts, they can introduce malware by exploiting an output integrity attack. After copying their malware to the target system, the classifier will classify the binary as malicious. The attacker then manipulates the model's output to the label benign instead of malicious. Subsequently, the succeeding system does not delete the malware as it assumes the binary was not classified as malware.
Model Poisoning (ML10)
While data poisoning attacks target the model's training data and, thus, indirectly, the model's parameters, model poisoning attacks target the model's parameters directly. As such, an adversary needs access to the model parameters to execute this type of attack. Furthermore, manipulating the parameters in a targeted malicious way can be challenging. While changing model parameters arbitrarily will most certainly result in lower model performance, getting the model to deviate from its intended behavior in a deliberate way requires well-thought-out and nuanced parameter manipulations. The impact of model poisoning attacks is similar to data poisoning attacks, as it can lead to incorrect predictions, misclassification of certain inputs, or unpredictable behavior in specific scenarios.
For more details regarding an actual model poisoning attack vector, check out this paper.
Manipulating the Model
Now that we have explored common security vulnerabilities that arise from improper implementation of ML-based systems let us take a look at a practical example. We will explore how an ML model reacts to changes in input data and training data to better understand how vulnerabilities related to data manipulation arise. These include input manipulation attacks (ML01) and data poisoning attacks (ML02).
We will use the spam classifier code from the Applications of AI in InfoSec module as a baseline. Therefore, it is recommended that you complete that module first. We will use a slightly adjusted version of that code, which you can download from the resources in this section. Feel free to follow along and adjust the code as you go through the section to see the resulting model behavior for yourself.
Manipulating the Input
The code contains training and test data sets in CSV files. In the file main.py, we can see that a classifier is trained on the provided training set and evaluated on the provided test set:
Code: python
model = train("./train.csv")
acc = evaluate(model, "./test.csv")
print(f"Model accuracy: {round(acc*100, 2)}%")
Running the file, the classifier provides a solid accuracy of 97.2%:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.pyModel accuracy: 97.2%
To understand how the model reacts to certain words in the input, let us take a closer look at an inference run on a single input data item. We can utilize the function classify_messages to run inference on a given input message. The function also supports a keyword argument return_probabilities, which we can set to True if we want the function to return the classifier's output probabilities instead of the predicted class. We will look at the output probabilities since we are interested in the model's reaction to the input. The function classify_messages returns a list of probabilities for all classes. We are using a spam classifier that only classifies into two classes: ham (class 0) and spam (class 1). The class predicted by the classifier is the one with the higher output probability.
Let us adjust the code to print the output vulnerabilities for both classes for a given input message:
Code: python
model = train("./train.csv")
message = "Hello World! How are you doing?"
predicted_class = classify_messages(model, message)[0]
predicted_class_str = "Ham" if predicted_class == 0 else "Spam"
probabilities = classify_messages(model, message, return_probabilities=True)[0]
print(f"Predicted class: {predicted_class_str}")
print("Probabilities:")
print(f"\t Ham: {round(probabilities[0]*100, 2)}%")
print(f"\tSpam: {round(probabilities[1]*100, 2)}%")
When we run this code, we can take a look at the module's output probabilities, which is effectively a measurement of how confident the model is about the given input message:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.pyPredicted class: Ham
Probabilities:
Ham: 98.93%
Spam: 1.07%
As we can see, the model is very confident about our input message. This intuitively makes sense, as our input message does not look like spam. Let us change the input to something we would identify as spam, like: Congratulations! You won a prize. Click here to claim: https://bit.ly/3YCN7PF. After rerunning the code, we can see that the model is now very confident that our input message is spam, just as expected:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.pyPredicted class: Spam
Probabilities:
Ham: 0.0%
Spam: 100.0%
In an input manipulation attack, our aim as attackers is to provide input to the model that results in misclassification. In our case, let us try to trick the model into classifying a spam message as ham. We will explore two different techniques in the following.
Rephrasing
Often, we are only interested in getting our victim to click the provided link. To avoid getting flagged by spam classifiers, we should thus carefully consider the words we choose to convince the victim to click the link. In our case, the model is trained on spam messages, which often utilize prices to trick the victim into clicking a link. Therefore, the classifier easily detects the above message as spam.
First, we should determine how the model reacts to certain parts of our input message. For instance, if we remove everything from our input message except for the word Congratulations!, we can see how this particular word influences the model. Interestingly, this single word is already classified as spam:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.pyPredicted class: Spam
Probabilities:
Ham: 35.03%
Spam: 64.97%
We should continue this with different parts of our input message to get a feel for the model's reaction to certain words or combinations of words. From there, we know which words to avoid to get our input past the classifier:
From this knowledge, we can try different words and phrases with a low probability of being flagged as spam. In our particular case, we are successful with a different scenario for the reasons outlined before. If we change the input message to Your account has been blocked. You can unlock your account in the next 24h: https://bit.ly/3YCN7PF, the input will (barely) be classified as ham:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.py Predicted class: Ham
Probabilities:
Ham: 57.39%
Spam: 42.61%
Overpowering
Another technique is overpowering the spam message with benign words to push the classifier toward a particular class. We can achieve this by simply appending words to the original spam message until the ham content overpowers the message's spam content. When the classifier processes many ham indicators, it finds it overwhelmingly more probable that the message is ham, even though the original spam content is still present. Remember that Naive Bayes makes the assumption that each word contributes independently to the final probability. For instance, after appending the first sentence of an English translation of Lorem Ipsum, we end up with the following message:
Congratulations! You won a prize. Click here to claim: https://bit.ly/3YCN7PF. But I must explain to you how all this mistaken idea of denouncing pleasure and praising pain was born and I will give you a complete account of the system, and expound the actual teachings of the great explorer of the truth, the master-builder of human happiness.
After running the classifier, we can see that it is convinced that the message is benign, even though our original spam message is still present:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.pyPredicted class: Ham
Probabilities:
Ham: 100.0%
Spam: 0.0%
This technique works particularly well in cases where we can hide the appended message from the victim. Think of websites or e-mails that support HTML where we can hide words from the user in HTML comments while the spam classifier may not be HTML context-aware and thus still base the spam verdict on words contained in HTML comments.
Manipulating the Training Data
After exploring how manipulating the input data affects the model output, let us move on to the training data. To achieve this, let us create a separate training data set to experiment on. We will shorten the training data set significantly so our manipulations will have a more significant effect on the model. Let us extract the first 100 data items from the training data set and save it to a separate CSV file:
Manipulating the Model
sasorirose@htb[/htb]$ head -n 101 train.csv > poison.csvAfterward, we can change the training data set in main.py to poison.csv and run the Python script:
Manipulating the Model
sasorirose@htb[/htb]$ python3 main.pyModel accuracy: 94.4%
As we can see, the model's accuracy drops slightly to 94.4%, which is impressive for the tiny size of the training data set. The drop in accuracy can be explained by the significant reduction in training data, making the classifier less representative and more sensitive to changes. However, this sensitivity to changes is exactly what we want to demonstrate by injecting fake spam entries to the data set (poisoning). To observe the effect of manipulations on the training data set, let us adjust the code as we did before to print the output probabilities for a single input message:
Code: python
model = train("./poison.csv")
message = "Hello World! How are you doing?"
predicted_class = classify_messages(model, message)[0]
predicted_class_str = "Ham" if predicted_class == 0 else "Spam"
probabilities = classify_messages(model, message, return_probabilities=True)[0]
print(f"Predicted class: {predicted_class_str}")
print("Probabilities:")
print(f"\t Ham: {round(probabilities[0]*100, 2)}%")
print(f"\tSpam: {round(probabilities[1]*100, 2)}%")
If we run the script, the classifier classifies the input message as ham with a confidence of 98.7%. Now, let us manipulate the training data so that the input message will be classified as spam instead.